Experiences in building cloud-native businesses: the Ticketmatic case
The Distrinet Research Group at my alma mater KULeuven invited me to speak at one of their DistriNet R&D Bites sessions on Nov 29 (2017). The main theme of this talk was about how Ticketmatic is a cloud-native business, what exactly that means and what we gain by it. An annotated version of the slides is below. If you’d rather just get the whole presentation as a PDF: get it here.


I’m Ruben, an engineer at Ticketmatic. More info about me.

Cloud Native, it’s the big hype of the moment in systems software. Today will not be a formal introduction to it, but rather our experiences and some of the cool things it enables us to do.
Just to situate what “us” means, I am one of the people that builds Ticketmatic:
Ticketmatic is a software-as-a-service provider of ticketing software. We focus on more complex ticketing setups and give our customers full ownership and flexibility to work with their data.
We’re currently based in Belgium and The Netherlands, but we’re also setting up shop in San Francisco.
To give an idea what our product looks like:
We have highly customizable sales pages.
There’s a full boxoffice and administration interface.
Which contains some cool visualizations.
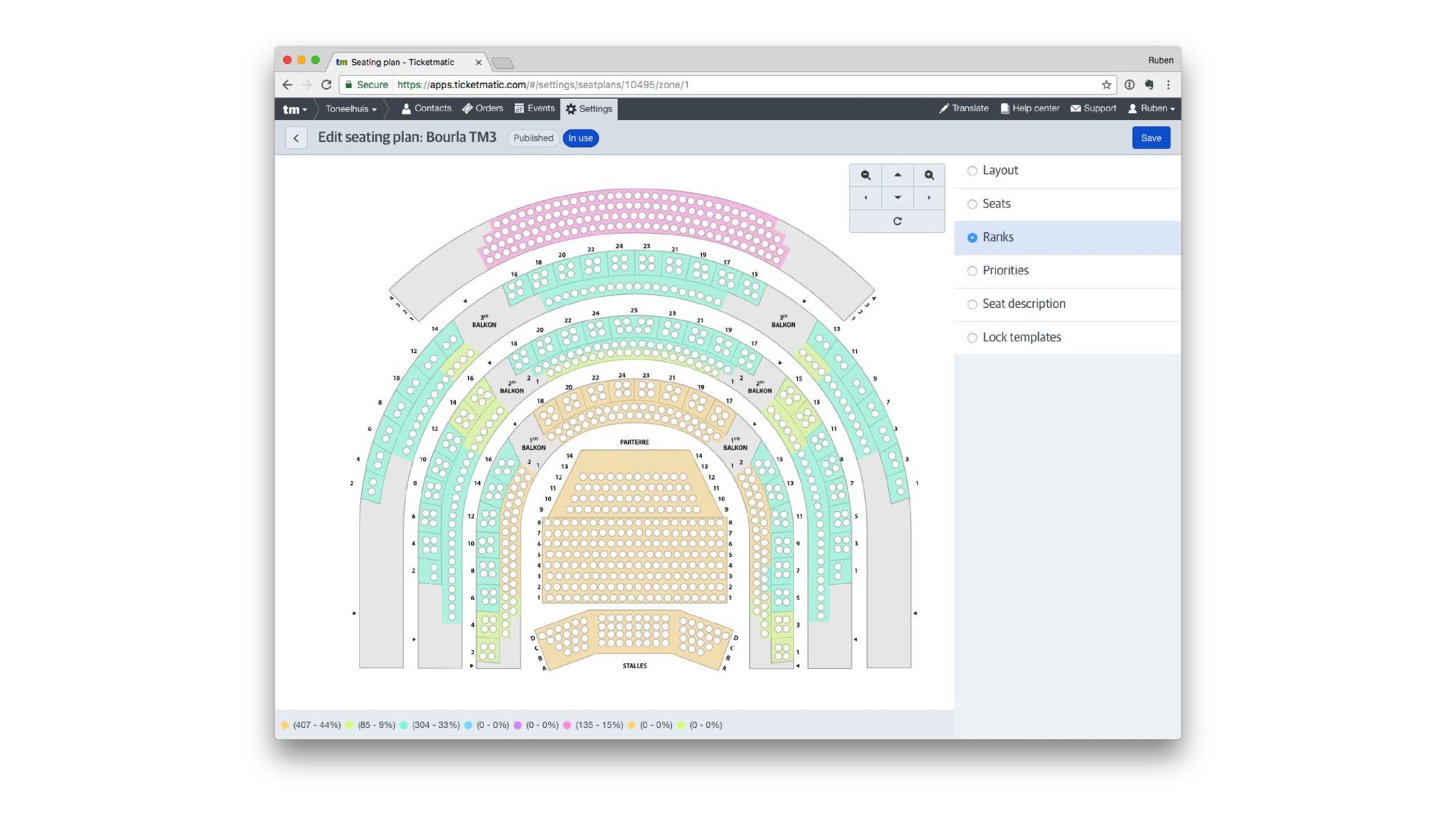
And some highly interactive editors. This one is a seating plan editor used to assign different classes of seating.

But at the core it’s just a big web application. And that means most of our experiences will also apply to other industries.
The interesting thing about software architecture nowadays is that with almost every application moving to the web/cloud in some form, all applications gradually converge on the same multi-tiered architecture. Some frontends, some backend services and even more services behind that.
So nothing specific to ticketing in this talk, just good old software engineering.

Cloud Native. What do you mean?

Roughly speaking: it’s good practices for building modern web-based application, all related to the management and infrastructure side of things.

Or if you want a more formal definition, here’s the one used by the Cloud Native Computing Foundation (CNCF), which is an umbrella organization that governs many of the open-source projects that are core to the Cloud Native philosphy. The CNCF in itself is part of the broader Linux Foundation.

For us it’s mostly a set of technologies plus a way of working that enables us to move faster and be more flexible.
I’ll illustrate this a bit more and gradually work towards some of the principles we believe in.

To get to the first one, we need to take a trip down memory lane and have a look at the evolution of how the software industry managed infrastructure as well as the applications running on top of that infrastructure.

In a not so distant past, we tended to have real hardware in data centers. Awesome, powerful machines that made a lot of noise. Worked really well, but they had a couple of disadvantages:
- Things always break at 4 in the morning, leading to a lightly trip to the most glorious office.
- Want to scale up? That means physically attaching more machines and cables. Forget about doing that quickly.
In parallel, application management used to be a manual afair: somebody had a spreadsheet that indicated which workloads ran on which machines. When things went haywire, manual intervention saved the day.

Then the cloud came along, most notably the Amazon EC2. Things were better now: somebody else fixes the hardware when things break and you can get all the hardware you want right from your couch.
This also led to a change in how we built software, due to the newly-gained “elastic” possibilities.
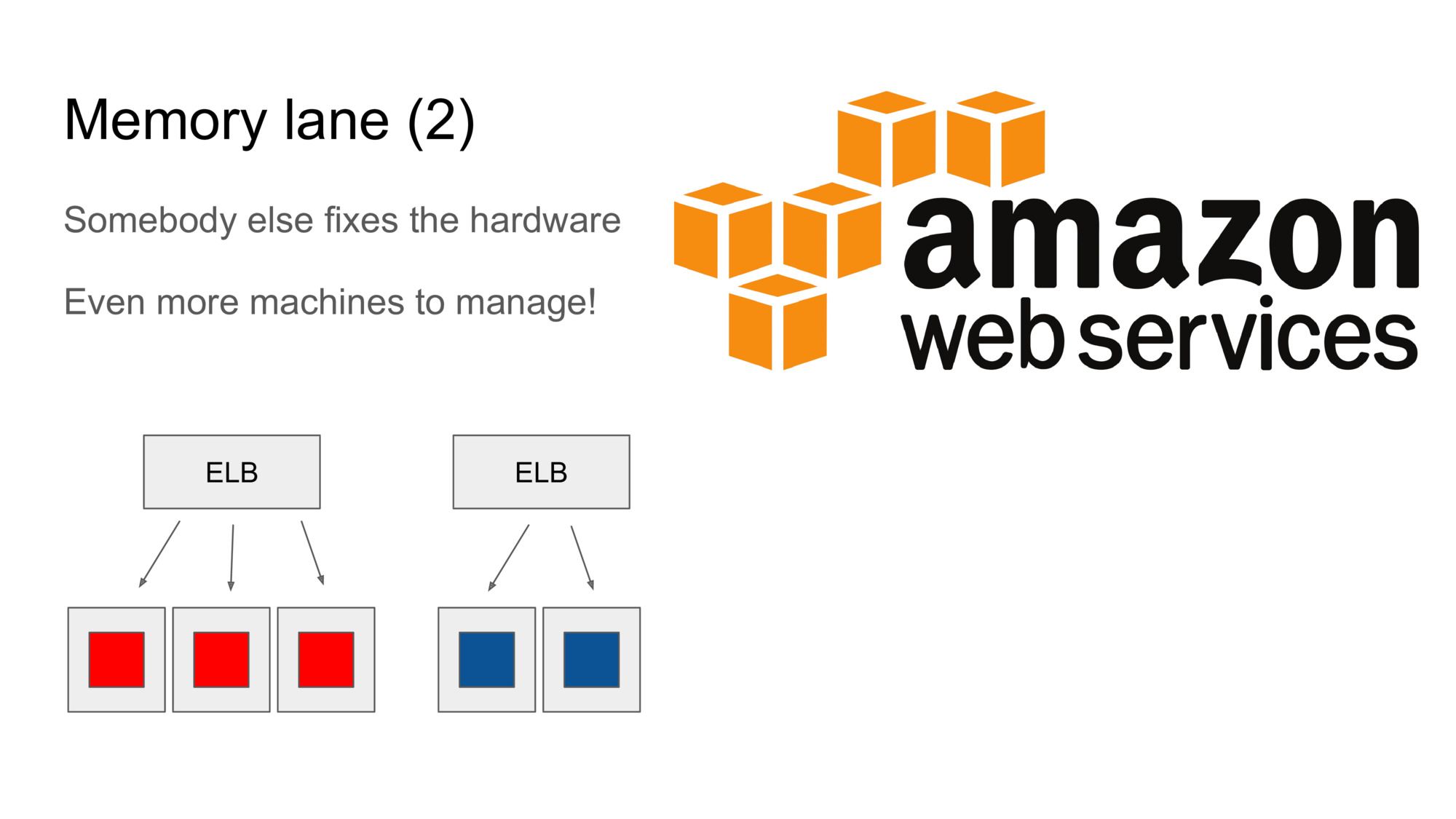
Rather than putting as much work as possible onto each machine, we’d start to put exactly one workload on each machine. Machines were then configured into auto scaling groups, which could spawn or destroy machines according to demand (usually measured by system load).
Load balancers were placed in front of each auto scaling group, to automatically distribute the work across the different machines.

So suddenly we had much more machines, smaller ones.
And there were load balancers everywhere, which had to be configured for each scaling group (every service in your application).
To make this work, each workload had to be baked into a separate machine image (quite cumbersome!).
So the state of the art was suddenly a lot more flexible. It was also a lot more complex, with different moving parts, which made it more difficult to administer. A big problem here was the mismatch between environments: what is running in production bears no resemblence to what is running on the laptops of developers. When the application architecture changes (e.g. a new service), modifications have to be made to each environment.

Docker was presented as a solution to this environment mismatch problem. It was coined “the universal shipping container of software”. This slide was one of the ways they illustrated what Docker does: you package your application into a container and no matter what workload it contains, it’ll slot in in any environment.

Many of the harder challenges were not solved by Docker. In fact, it’s mostly a packaging format, like a zip file.
So your application was suddenly more portable, but everything around it was still manual work.

At this point Kubernetes was announced by Google. Kubernetes is an open-source cluster infrastructure, based on their many years of experience related to running large scale web applications (there’s probably no other company that does this better). It takes the best concepts from their internal cluster software (Borg, Omega) and builds upon those.

Kubernetes takes your machines and abstracts them as a “cluster”. It means you no longer have to think about individual machines. The three machines drawn above represent our cluster.
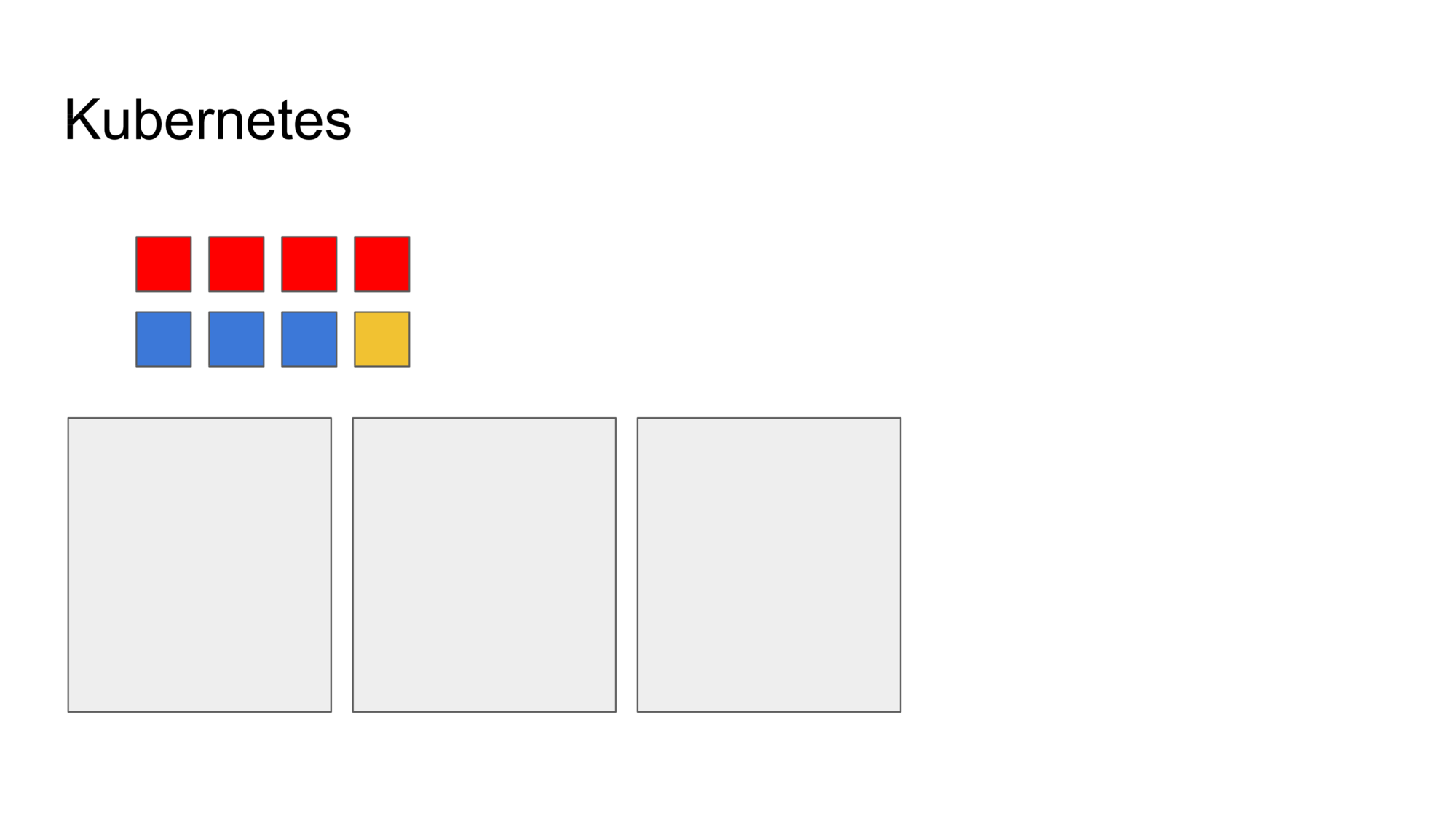
You then define your workload, declaratively (I’ll show an example of a configuration file later). Here I have three workloads (services): a red one (4 copies), a blue one (3 copies) and a yellow one (just one copy).
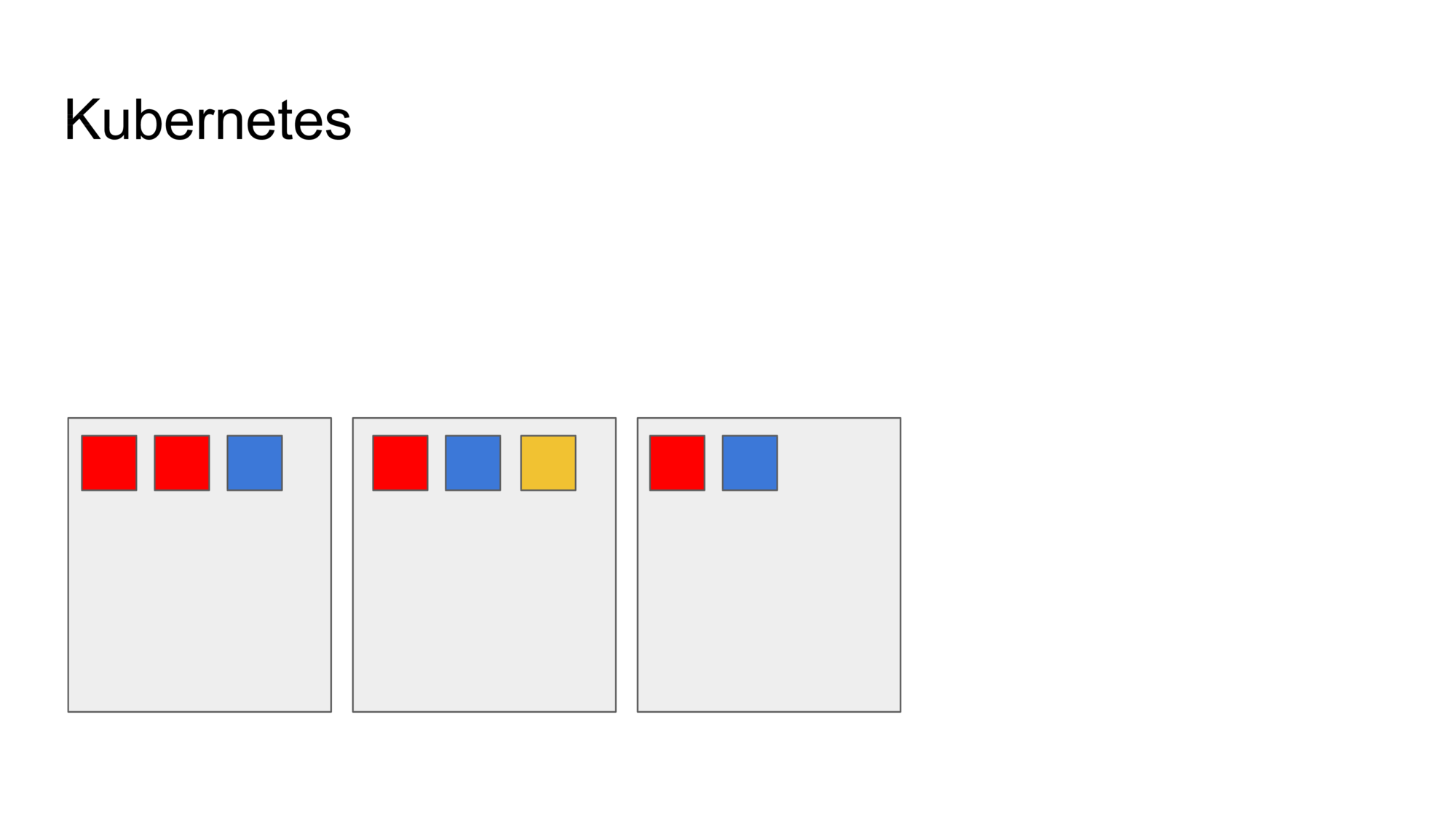
I hand these over to Kubernetes, which then decides what goes where. It also wires up everything so that each service can talk to eachother, regardless of which machine it is on.
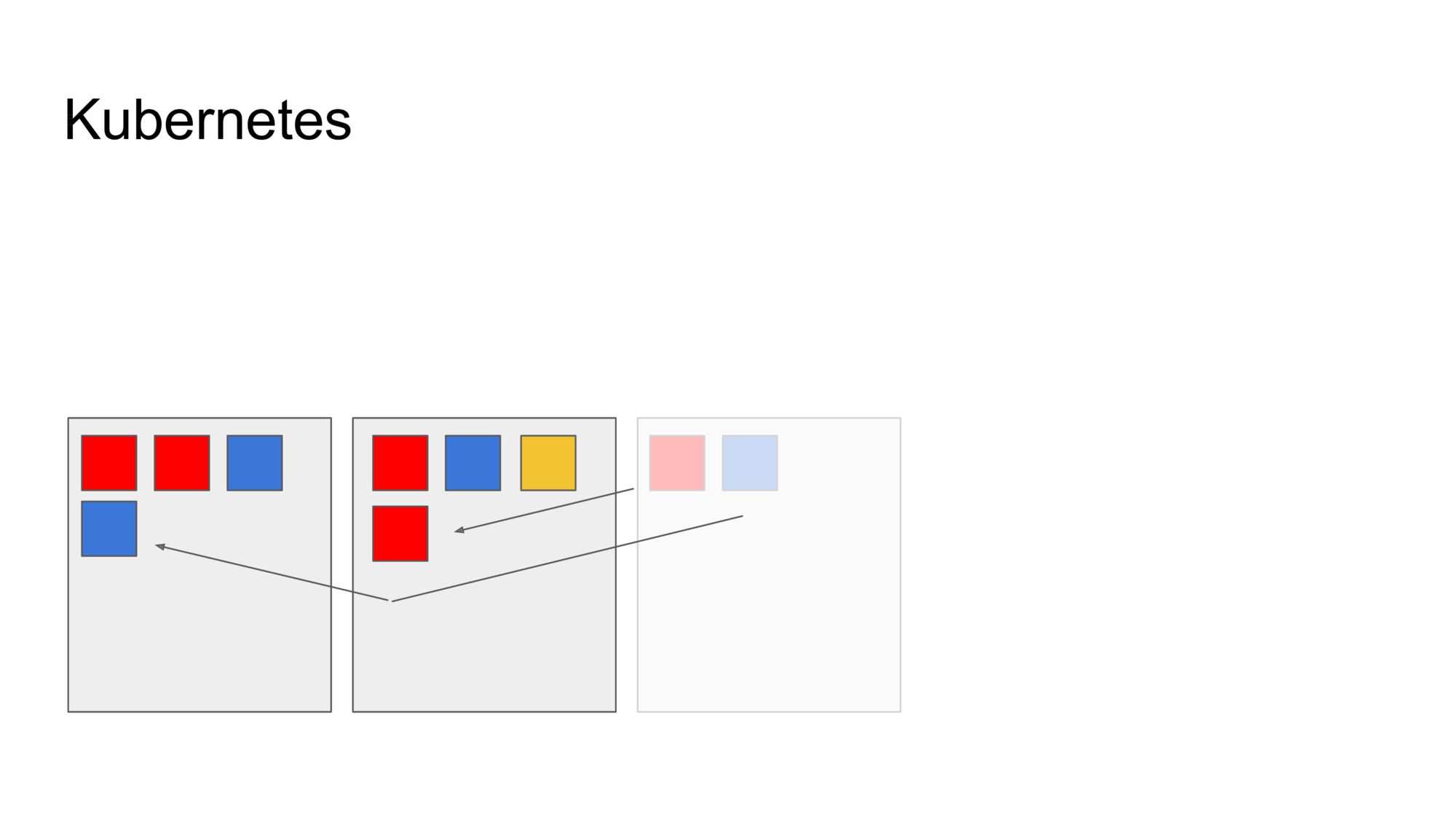
And because it is all declaritively defined, Kubernetes is capable of reasoning about this configuration. If a machine goes down, it knows what it needs to do to restore the system into the desired state: move the missing instances to other machines.
You can also defined scaling policies, allowing Kubernetes to control the number of copies for you, depending on the system load.
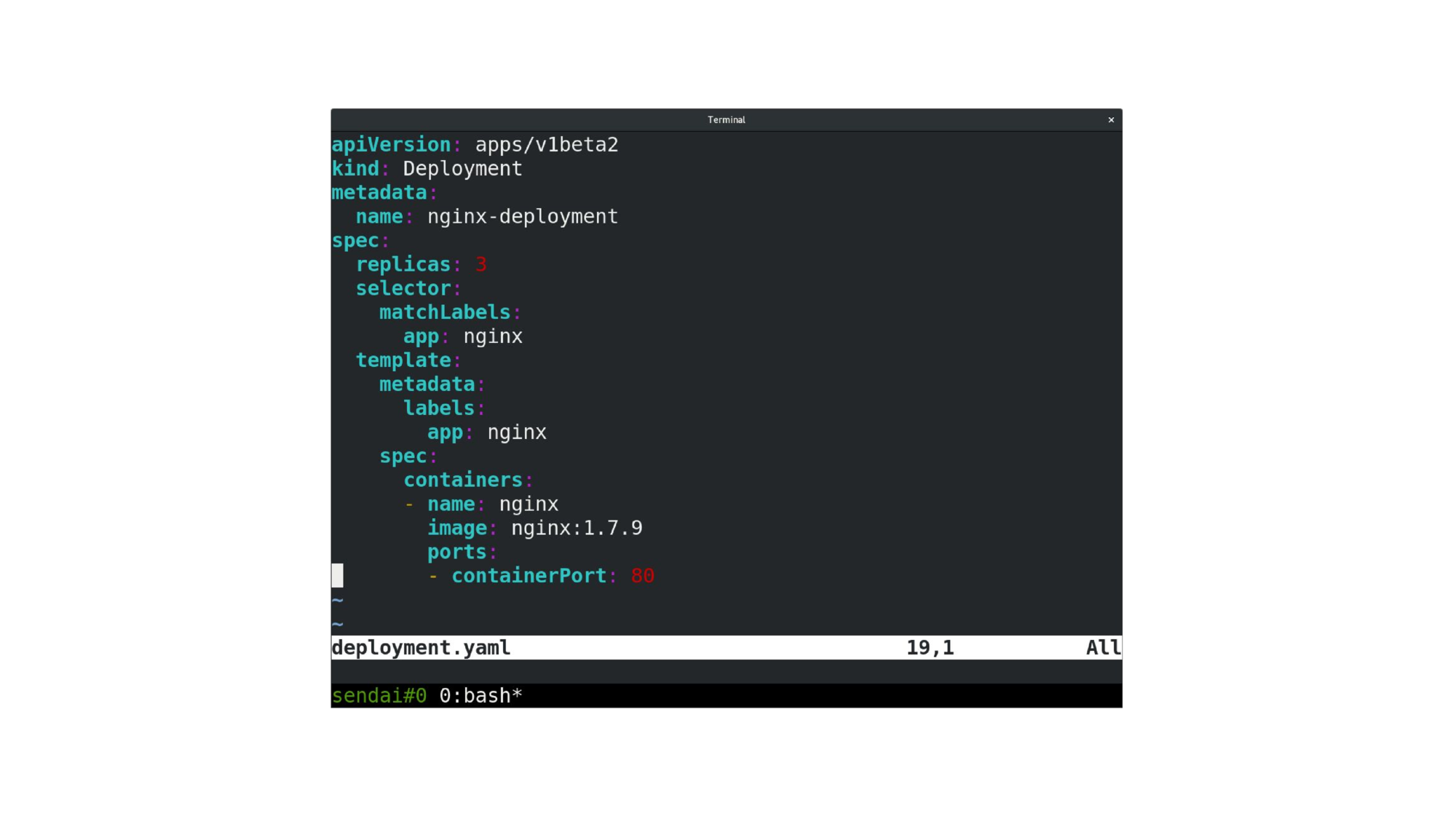
Configurations are defined using YAML or JSON files. One of them is shown here: most of it is metadata (it’s there for a reason, but I’ll spare you the details), the more important stuff is near the bottom: it defines which Docker containers should be used.

One obvious advantage is that we’ve increased the density again: multiple workloads can be combined onto a machine, leading to less waste. But this time you don’t have to do it manually: the cluster scheduler takes care of that.
In fact, the cluster scheduler is capable of doing pretty much all the work for you, thanks to the declaritive orchestration. It constantly observes the cluster state and reconsolidates it with the desired state.
This can lead to interesting effects: we had one of our services randomly crashing after a couple of minutes of running. Kubernetes saw it happening and spawned new instances of this service. Because it did this constantly, no downtime was incurred and none of our users noticed.
The most important gain is portability for the application and the way it’s wired together. We have a Kubernetes cluster in production, but also on our developer laptops. The same configuration is used to run the application stack in both environments. This configuration is versioned and roll-outs happen automatically, so evolution of the application structure in development automatically gets mirrored in production whenever we trigger a deployment.

And this brings us to our first principle: operations should be automated. It reduces work, but crucially, it also reduces the risk for errors. We’re a small team and we don’t want an on-call rotation that constantly pages us at night. But most of all we want to be able to move fast and change things, without the risk of breaking things and making mistakes.

Quick intermezzo about micro-services (you could call it a personal rant).

Remember how the CNCF definition mentioned micro-services? Everybody’s talking about it nowadays and there’s good reasons for that.
But I’d like to urge people to find a good balance: keep your services cohesive but know that having too many of them makes things horribly complex.
So we don’t split off a ForgotPasswordService or any of that nonsense. Our services are fairly large, but we do split them: where it makes sense.
A good rule of thumb for where you should slice your services: when you want to scale them on different schedules / proportions.

Back to Cloud Native.
What we’ve just seen is already a good way of running your software in the cloud. But we’re not there yet, it’s still an application running on top of an infrastructure. We can do more to take advantage of the unique properties of the environment we’re running in.

Kubernetes has an API. You can use it to fetch information about your cluster, but it’s much more powerful than that. It can also be used by your application itself (if you allow it to do so). This leads to interesting interactions between application and infrastructure.
Here’s an example:

We love PostgreSQL, probably the most awesome SQL database out there. There’s just one thing it’s less than ideal for: high volumes of short-lived connections. PostgreSQL spawns a new process for each connection you open, so if you have a lot of them, it’s going to be pretty painful.
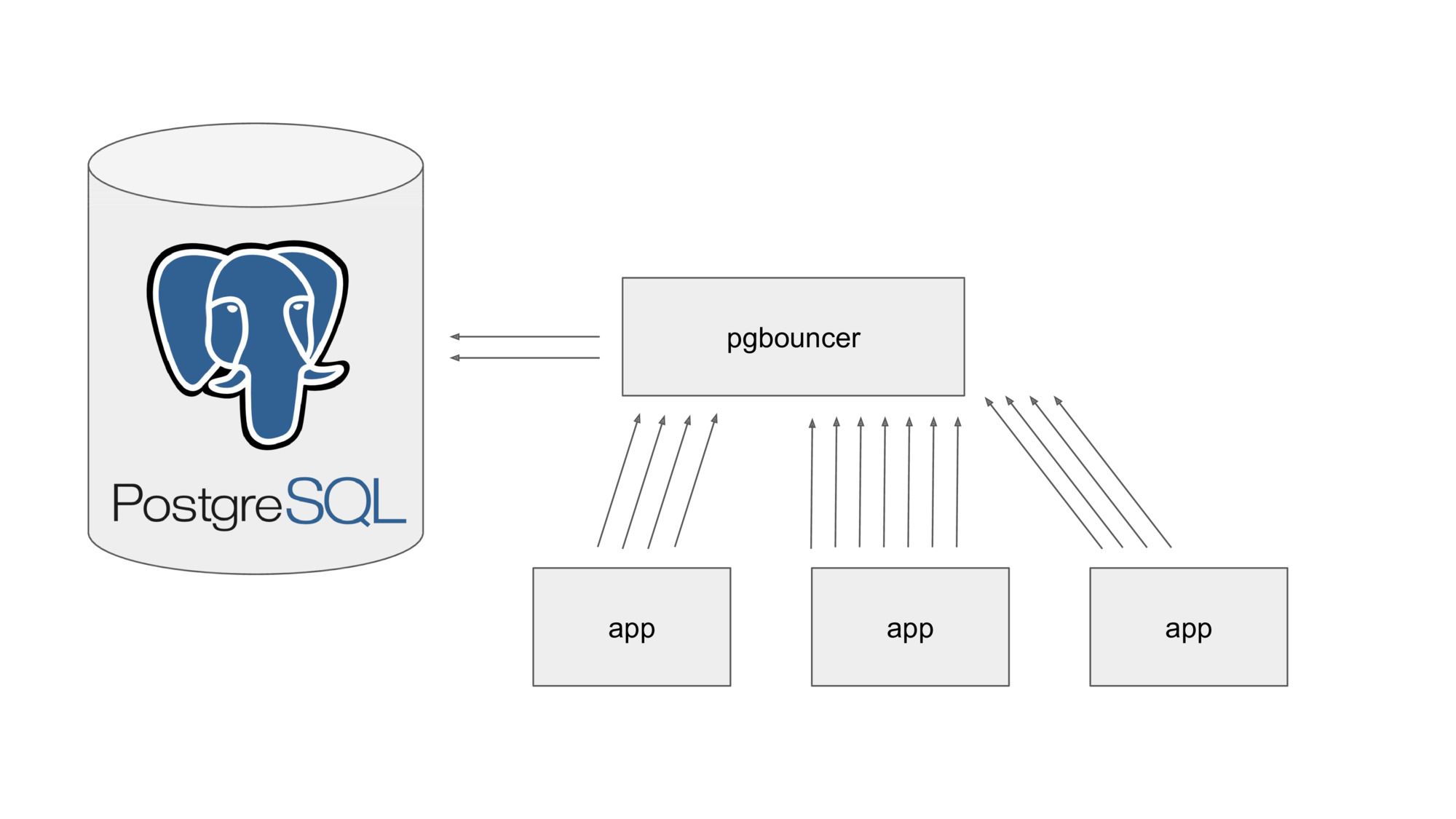
The usual way to solve this is to use pgbouncer, which pools many short-lived connections and multiplexes them over fewer long-lived connections. A simple way to make your database scale much further.
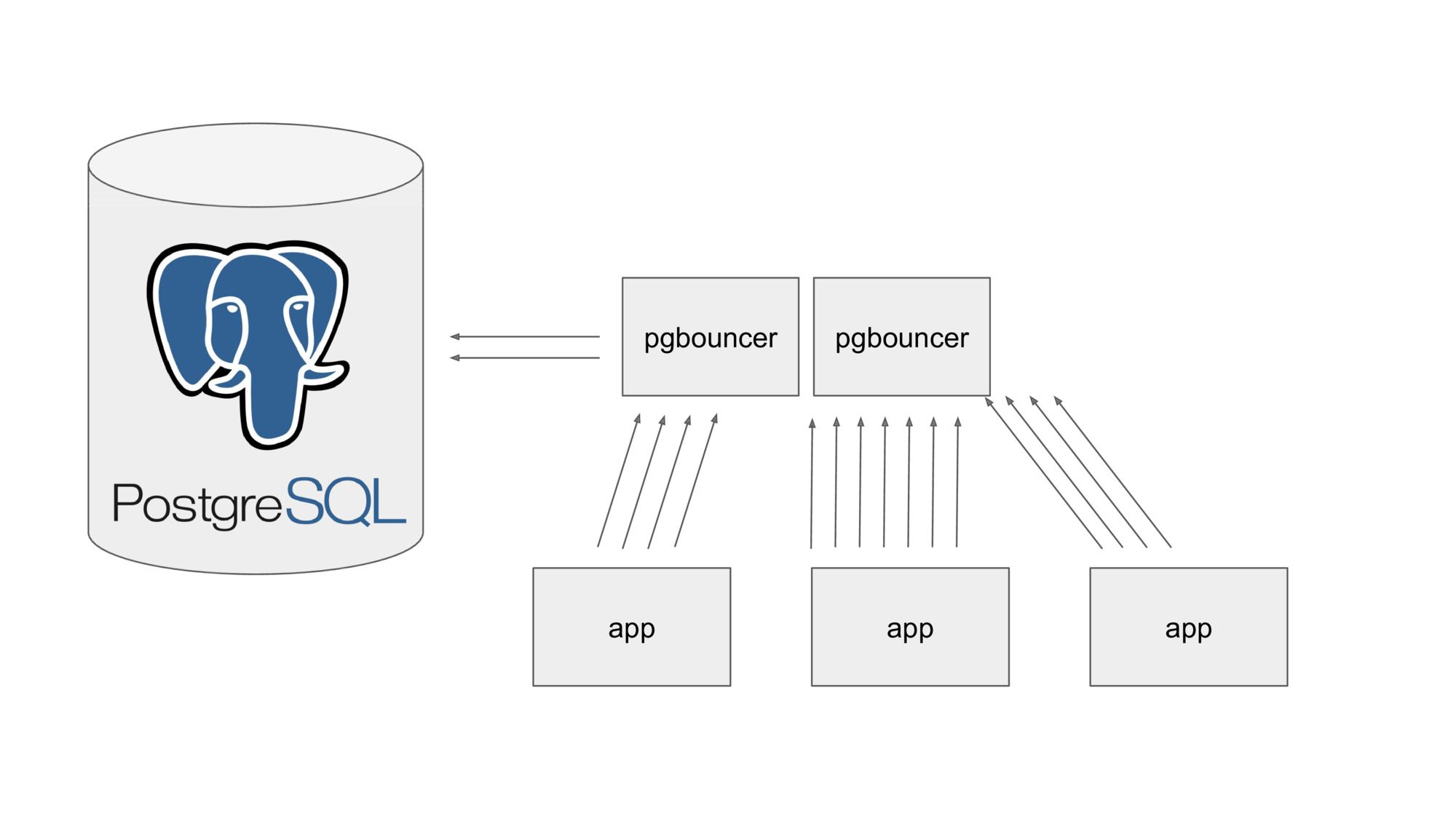
Machines tend to break, so if you want to be resilient, you’ll want to run more than one instance of pgbouncer. But the problem here is that there’s only a fixed capacity available between pgbouncer and the PostgreSQL database server. Running multiple pgbouncer instances means that each of them can only claim a portion of the available connections to the PostgreSQL database.
We could cleverly tune this value, but it’s never going to be ideal in all situations (e.g. when scaling up / down).
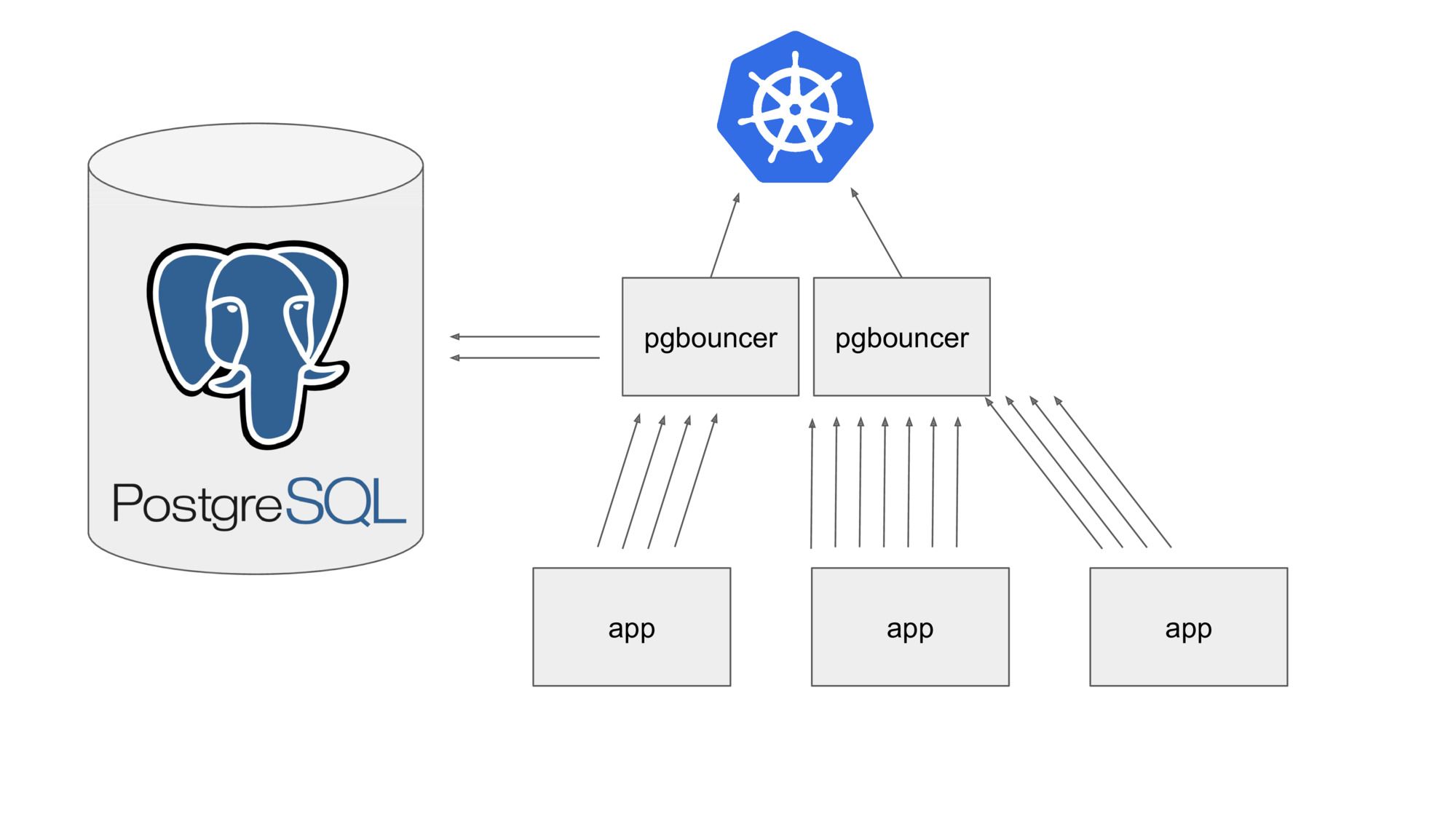
Instead, our pgbouncer service listens to the Kubernetes API and is notified instantly whenever the cluster changes. Whenever a pgbouncer goes away (be it through crashing or scaling down) or appears (by restarting or scaling up), each of them will immediately reconfigure itself to use the optimal pooling parameters.
Rather than manually tuning our database setup, we now have one that is capable of administring itself.

Applications should be allowed to interact with the infrastructure: it opens up a whole new array of possibilities.

We can take this idea one step further by introducing Prometheus.

Prometheus is another CNCF project: an open-source monitoring platform, which allows you to instrument your applications and gather all kinds of metrics. It’s designed for dynamic environments such as a Kubernetes cluster and optimized to collect large amounts of metrics. That way you don’t have to choose: measure everything.

Measuring everything is important because it gives you vital knowledge about what is happening in your application. Without instrumentation you are effectively flying blind.

Good instrumentation also allows you to have much more powerful interactions with your infrastructure, based on the actual application state.
Here’s an example. Ticketing has a highly peaky performance profile. You could barely have any visitors all day, then suddenly half the country is refreshing your sales pages like crazy. Makes it pretty difficult to scale effectively, as the ramp-up usually goes really really quick. But the signs are there: if you track the number of people arriving (and staying) at your sales pages, it’s very doable to see where the herd is going to arrive. This buys you valuable extra time to scale up, right when it’s needed.
Using only system metrics (such as CPU load) won’t work here: the initial arrivals aren’t large enough to trigger real load-based scaling. But the application metrics paint a clear picture.

Operations now has a new role. Where it used to be mostly reactive grunt work in the past, it’s now a higher level role, analysing trends and discovering patterns, which are then codified into rules.

And this leads us to the final principle: everybody is operations. It’s no longer purely a concern for system administrators. Nor is the infrastructure something developers can simply ignore (“They’ll just get a bigger database server!”). It’s something everybody has to think about, all the time.
But at the same time nobody is operations. We should think about it, but never do it ourselves. Rather, we should build the system such that it operates autonomically.


Cloud Native is a new way of looking at your infrastructure. Applications and infrastructure aren’t separate things anymore: each influences the other. And central in this is the role of the developer, who automates the operations role. This frees operators to focus on gaining insight and defining new and better ways for the infrastructure and application to manage itself.

If you found this interesting, I recommend you have a look at the talk I gave last July at CoreOS Fest 2017 in San Francisco. It goes much more into depth on how we use, manage and deploy Kubernetes.
The talk also covers our very powerful development environment. It’s a miniature Kubernetes cluster running on each developer laptop, with the full application stack. A dashboard allows interacting with each component and gives developers the option of linking local source code into the cluster, which leads to a “livereload for backend services”-kind of experience.

That’ll be all for today. Thanks for following along!