Making your company cloud‑native: the Ticketmatic story
On May 31 (2017), I gave a talk at CoreOS Fest 2017 in San Francisco about how Ticketmatic adopted the cloud and Kubernetes. An annotated version of the slides is below. If you’d rather just get the whole presentation as a PDF: get it here.
Watch the video recording below, or scroll past it to read the annotated version.
Without further ado, let’s get going:


I’m Ruben, an engineer at Ticketmatic. More info about me.

Ticketmatic is a software-as-a-service provider of ticketing software. We focus on more complex ticketing setups and give our customers full ownership and flexibility to work with their data.
We’re currently based in Belgium and The Netherlands, but we’re also setting up shop in San Francisco.
To give an idea what our product looks like:

We have highly customizable sales pages.
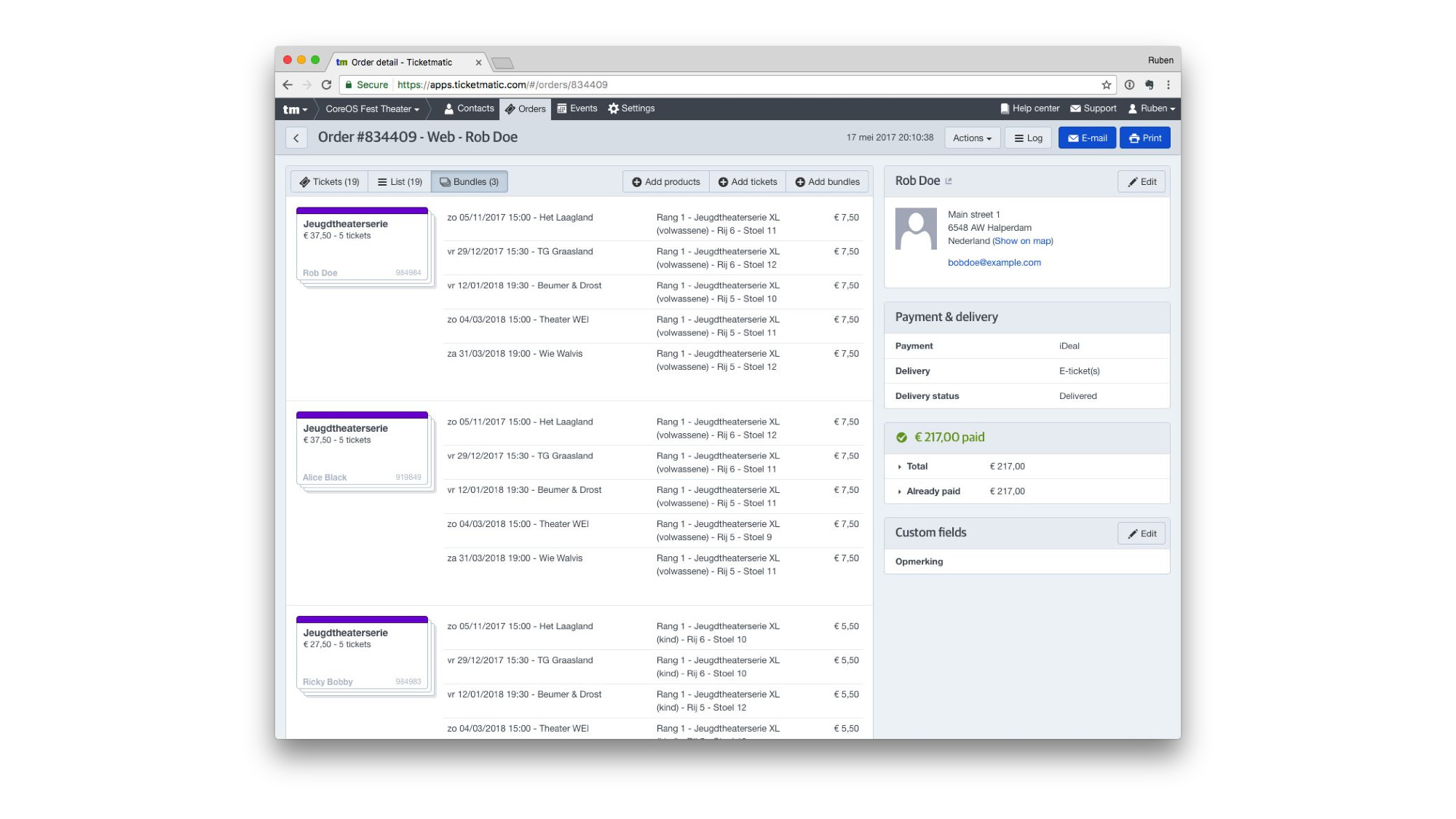
There’s a full boxoffice and administration interface.
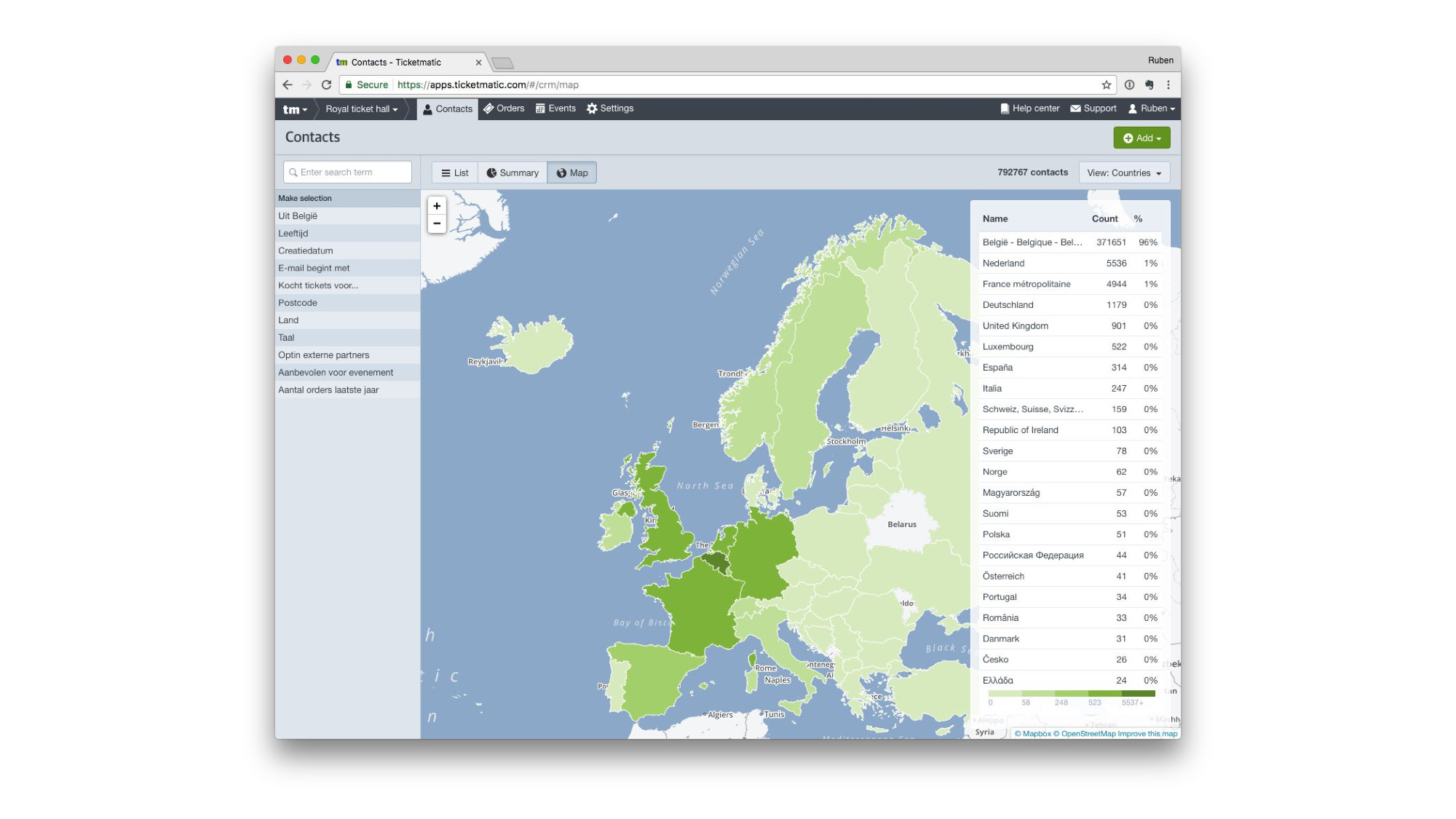
Which contains some cool visualizations.
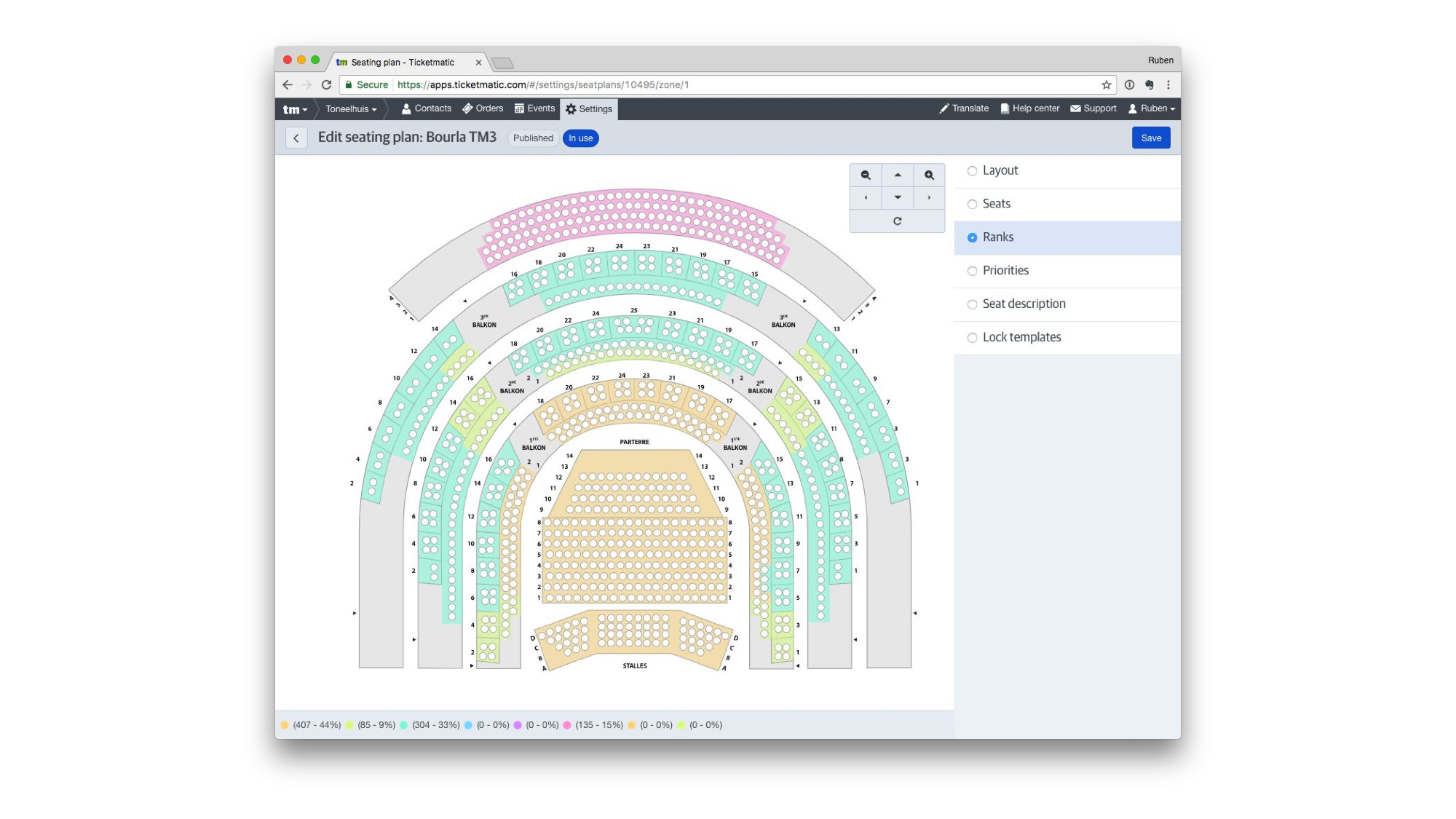
And some highly interactive editors. This one is a seating plan editor used to assign different classes of seating.
As you can see, all of this runs in a web browser. It’s at the core just one big web application.

Today I’ll be talking about how we made our company cloud-native, using Kubernetes.

And to better understand why we did certain things, you need to know where we came from.
Like most IT companies we were running our own servers in multiple data centers. Which is okay, until things break. And that usually happens around 3 or 4 o’clock in the morning on a Sunday. The data center is our most glorious and dreaded office.
The application stack was a classic LAMP stack: just a pile of PHP with a database behind it. We’re still dragging some of that PHP along (don’t break things that aren’t broken), but we’ve since grown into a strategically sliced monolith. So not full microservices, just the parts that make sense split off. New development generally happens using Go.
The biggest pain was in the management side of things. Deploying the software was a matter of running rsync to send code to the right machines in the right locations, manually installing packages and running the right scripts in the right order. Not ideal and certainly not error-free.
There was also a big pain in terms of keeping environments in sync. If you have a development environment, a staging environment and a production environment, you’ll need some way to mirror the software evolution in one environment into the next one. Without a good way to handle this, it quickly leads to trouble.

At that point Docker came along. This slide comes from the material they used when Docker was first introduced. They reasoned that there’s a big problem in software: for each different combination of types of software and types of runtime environment, you needed a different software artifact. This quickly becomes unwieldy.
Docker was introduced as the universal shipping container of software. The one shape that allows your software to fit in anywhere.
That’s great right? Solves a big problem! Except…

It didn’t really. Back at the time (they’re making things better now), there was nothing in Docker to help with deployment of software. You still had to manually start the right containers on the right machine (all manual, obviously).
And if you have multiple machines, there’s no real way to make them work together. Nor is there a good way to orchestrate multiple pieces of software together.
It turns out that the universal shipping container is just that: a packaging format. We need more than that.

So when Kubernetes came along, it really struck a chord. Based on many years of experience at Google, arguably one of the few companies that have really nailed how to build and run large scale software, it promised to provide a solution for many of these hard problems.
Kubernetes sounded exactly what we need, so we set out to evaluate it.

So today will be our story, what we learned along the way, some of the problems we ran into and how we solved them.
But it might just as well be your story. Apart from some special needs related to ticketing, our software is a fairly standard web architecture, as most companies have today. So if you’ve done the same thing, you might have had very similar experiences.

Step 1 is to get the cluster running. And we must really pay respect to CoreOS here: Container Linux solves a real need and beautifully solves the problem of OS maintenance. But not only that: the documentation provided by CoreOS on how to run Kubernetes is top notch. Really made setting up a cluster a walk in the park.
We didn’t use Tectonic, though we did evaluate it. Back then it didn’t support a highly-available control plane. It does nowadays, so it might warrant another look.
And this positivity doesn’t just come from the fact that this talk is happening at CoreOS Fest, we truly like their products.

But then the confusion kicks in. We have this shiny new cluster running, we can run some demo applications on it and it’ll work fine, but we have no clue how to go from there.
Infrastructure is only part of the larger story of going cloud-native.

What about the operational side of things? Or the developer story?
These are the two areas I’d like to shed some light on.

Let’s start out with operations. It’s the first step up the ladder of abstraction from infrastructure: it’s the people and processes that interface with the infrastructure.
The Kubernetes CLI kubectl is a really great tool. In fact it’s the Swiss army knife of cluster management: you can do pretty much anything with it and it does those tasks really well.
But it’s also a bit too low-level. You’ll still be doing a lot of manual operations, there’s no real workflow in place.

And that leads to a number of operational difficulties. Keeping multiple environments in sync is still a manual process, with all the associated room for errors. What we really need is a reliable and repeatable (so we can test it) process to handle transitioning from one environment to the next.
We also want to have one set of configuration for our whole platform, regardless of where things are running. Having to maintain different slightly different configurations for each environment is a recipe for disaster.
For this reason we set out to find a solution for this problem. And what started out as a small prototype is now a stable tool that has stuck around for way longer than it should (as is mostly the case with these kind of things). But it works, well, so we like it.
What we built is called kube-appdeploy. It takes your set of Kubernetes manifests and treats them as a set of templates.
You can get it on GitHub: https://github.com/rubenv/kube-appdeploy
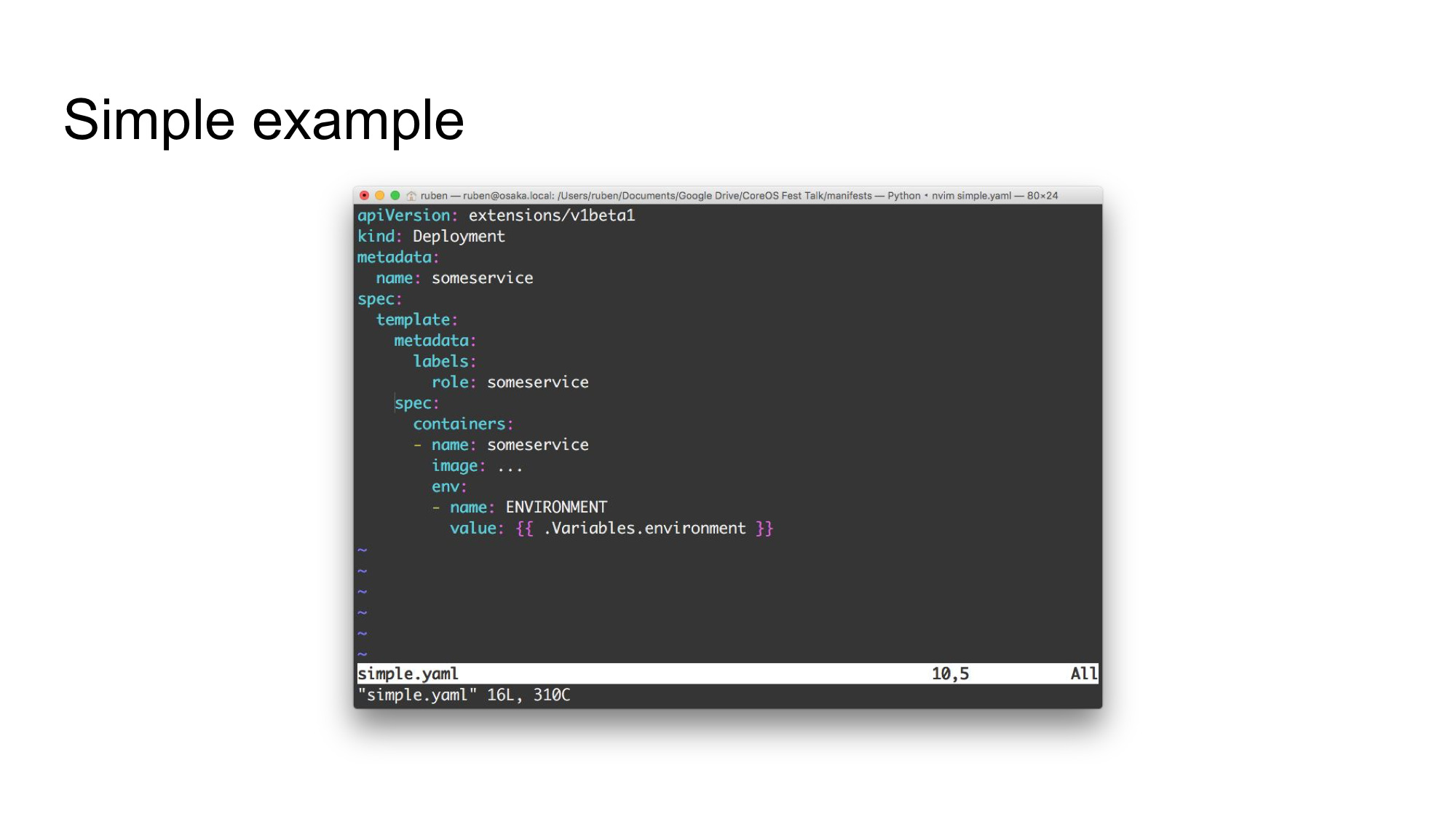
Here’s a simple example. It’s a simple standard Kubernetes deployment manifest, with one exception: there’s a variable defined on the last line: {{ .Variables.environment }}. This will be substituted when the manifest is deployed.
This is a very trivial example: it simply sets the value of an environment variable. But you can do more interesting thing as well. For instance, our continuous integration system keeps track of a list of the lastest built Docker images. We substitute references to these images into the deployment manifests. This means we don’t have to edit our deployment manifests for each release.
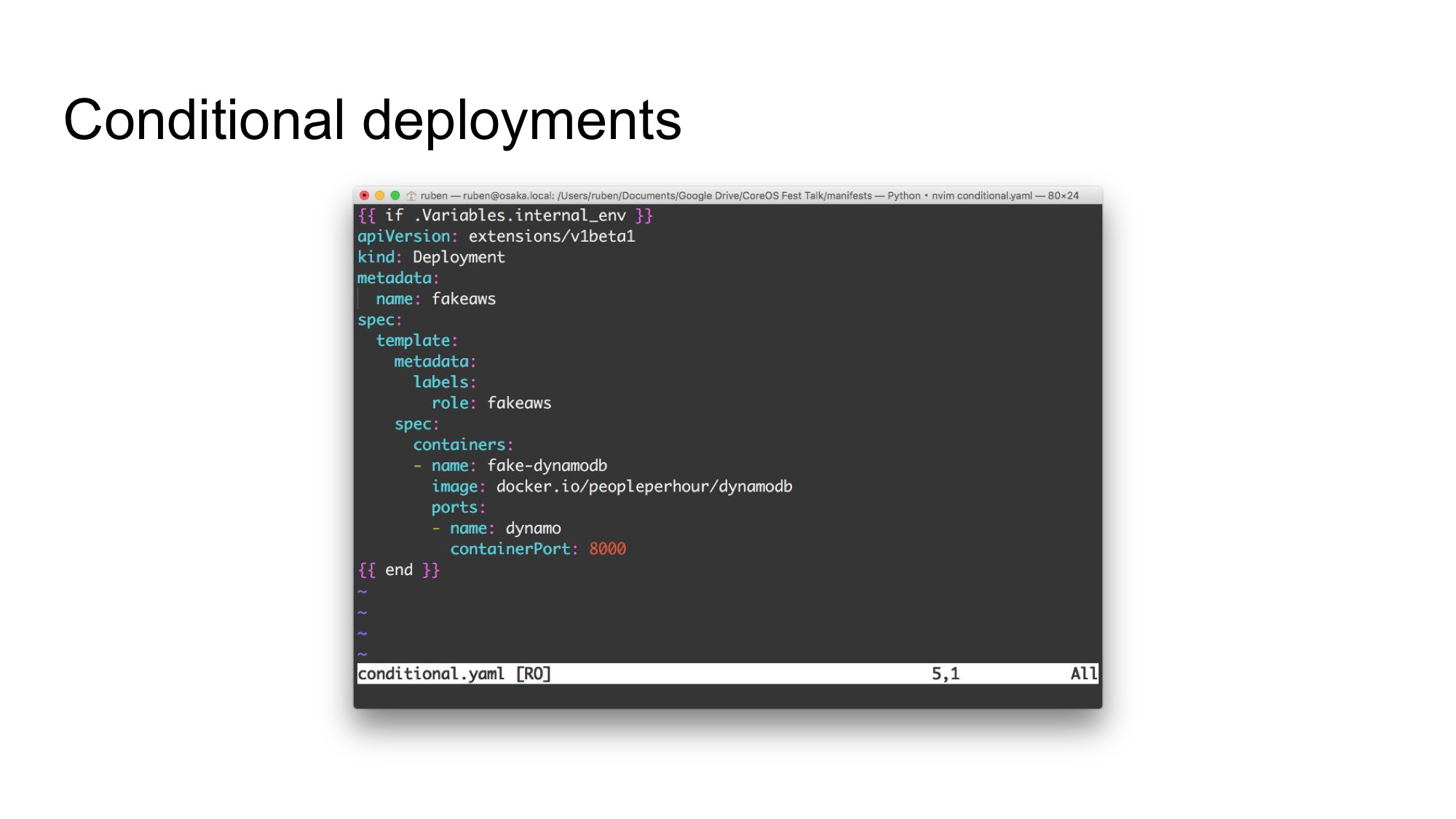
You can also use control flow. In this example we’ve wrapped the whole configuration definition in an if-block. If it evaluates to false, nothing will be output and the whole deployment is ignored. This makes it useful for those situations where you only want a service to be present in some environments. The example above shows a DynamoDB development server for use during local development. This obviously doesn’t need to be deployed to production, since you’ll use the AWS-provided version there.
You can use control flow anywhere in the manifests: these are just Go text/template templates.
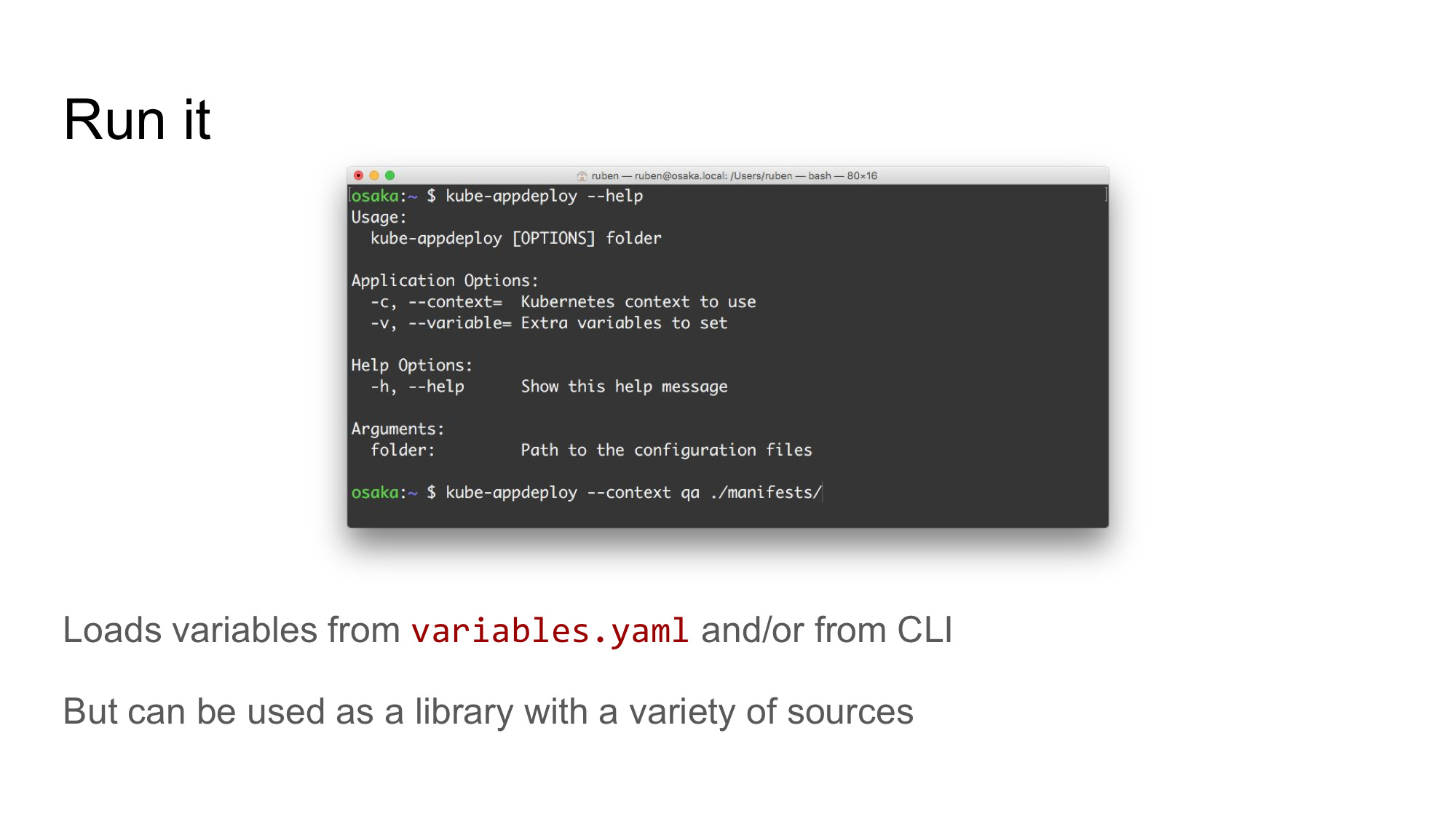
Deploying your application to a cluster can be done using the kube-appdeploy CLI app. Just point it to a folder that contains your manifest templates. Variables are loaded from variables.yaml (if present) and/or you can specify them on the command-line.
You can also use kube-appdeploy as a library, to integrate it into a bigger piece of software.
When deploying, ownership of the whole namespace is assumed. The templates are rendered using the supplied variables, resulting in a set of manifests. The desired state will then be compared with the state of your cluster, adding/updating/removing things if needed.

This trivial tool gives us a couple of big gains: we we can now have one set of manifests, regardless of the environment they run in. We’ve also taken most of the human interaction out of the processes, leaving less room for errors.

This might all seem very familiar if you know the Kubernetes ecosystem a bit. And that’s not surprising: it’s exactly the same thing Helm does.
Somehow we converged on the same solution, except Helm does a lot more, like life-cycle hooks. Our first encounter with Helm was when it was still alpha-quality. Kube-appdeploy was stable at that time, so we stuck with it. Probably for longer than needed, Helm is the way forward.

One other thing I want to mention is pod presets. It’s a relatively new and unknown feature of Kubernetes that allows you to centralize some pieces of configuration.
For instance, you might put a piece of configuration that uses a config map in a pod preset. This piece of configuration will then be added to each pod that gets scheduled in the cluster.
This might help simplifying your configuration by moving some pieces of repeated configuration into one place. Be careful not to over-do it though: have too much of this and it becomes rather difficult to see what the end result will be.
Pod presets also don’t help you when things need to be deployed conditionally. Nevertheless: it might help you, so do give it a look.

Kubernetes was built from the ground up: at first there were only pods, services and replication controllers (which became replica sets later on). Deployments were added later on, when these basic building blocks were stable and rock-solid. That’s a good way to do things: with infrastructure software you need to be able to depend on things, you can’t build things based on a house of cards.
This way of working has the disadvantage of leaving the things that are higher up on the ladder of abstraction (further away from the infrastructure) undefined (initially).
But progress is being made, that’s a good thing.

Let’s shift our focus to the development story.
The trouble here isn’t per se getting buy-in from developers: most developers working on backend services will quickly see the advantages of running on a cluster that has an API which allows applications to inspect / adjust themselves.
But there’s a group of developers that don’t touch infrastructure: people like the frontend developer, who might poke at some backend APIs sometimes, but for the most part is only interested in the functionality of the application.
These developers usually aren’t as excited by new infrastructure as the devops people.

And speaking from experience: making a developer miserable isn’t the best way to get buy-in for a new technology.
So we need to take care of the developer experience.

One of the difficulties here is that theory differs from reality most of the time. Especially in software development.
Microservices theory states that you should develop your services in isolation. Mock your dependencies, have good contracts in place and build a ton of unit tests.
In reality this usually doesn’t work out all that well. People will get the contract wrong and things won’t combine well when you get to the integration phase.
Or you might be in the situation where you need to work on (or debug) a complex interaction that runs over multiple services.

Either way, at some point you’ll need to have the whole environment (or a big chunk of it). That way you’ll be able to work on different services at the same time.

This becomes extra difficult when you adopt Kubernetes in your development environment. In a more traditional environment, you run everything on your local machine (with all the installation pain that comes with it). Move your development environment over to Kubernetes and it becomes a bit more complex / painful.
To see why, let’s have a look at the average developer workflow for a PHP developer. PHP is a horrible language, but it does come with a great developer workflow: write your code, hit save, issue a new request (or reload the page) and changes are instantly active. Can’t get much smoother than that.
Now imagine everything running in a Kubernetes cluster. After writing your code and saving the changes, you’ll need to:
- Build your software (e.g. for a Go project)
- Create a Docker image for it
- Upload that image to a container registry
- Create new pods or adjust the deployment, which in turn will roll new pods
It’s easy to see how each step adds more effort and slows things down.
We didn’t want to go for that, so the big question was: can we find some sort of live-reload for backend services?

In fact, the bigger goal was to have a better development environment. One that’s fully effortless: simply clone a git repository with the configuration and issue one command to start everything. Nothing else required and, importantly: no prior knowledge about Kubernetes etc required.
This means any developer can start using it right away, without extra training.

So we were going to build a developer tool at Ticketmatic.
After many creative thinking sessions, we came up with a perfect name:

Pinnacle of creativity, right?
Side-note: During discussion, Derrick from Mailgun pointed out that they call their development environment ‘devgun’. Great minds think alike, no? ;-)
I gave a live demo of the environment at this point. That’s a bit hard to embed here, so we’ll stick to screenshots. Let’s run down some of the features:
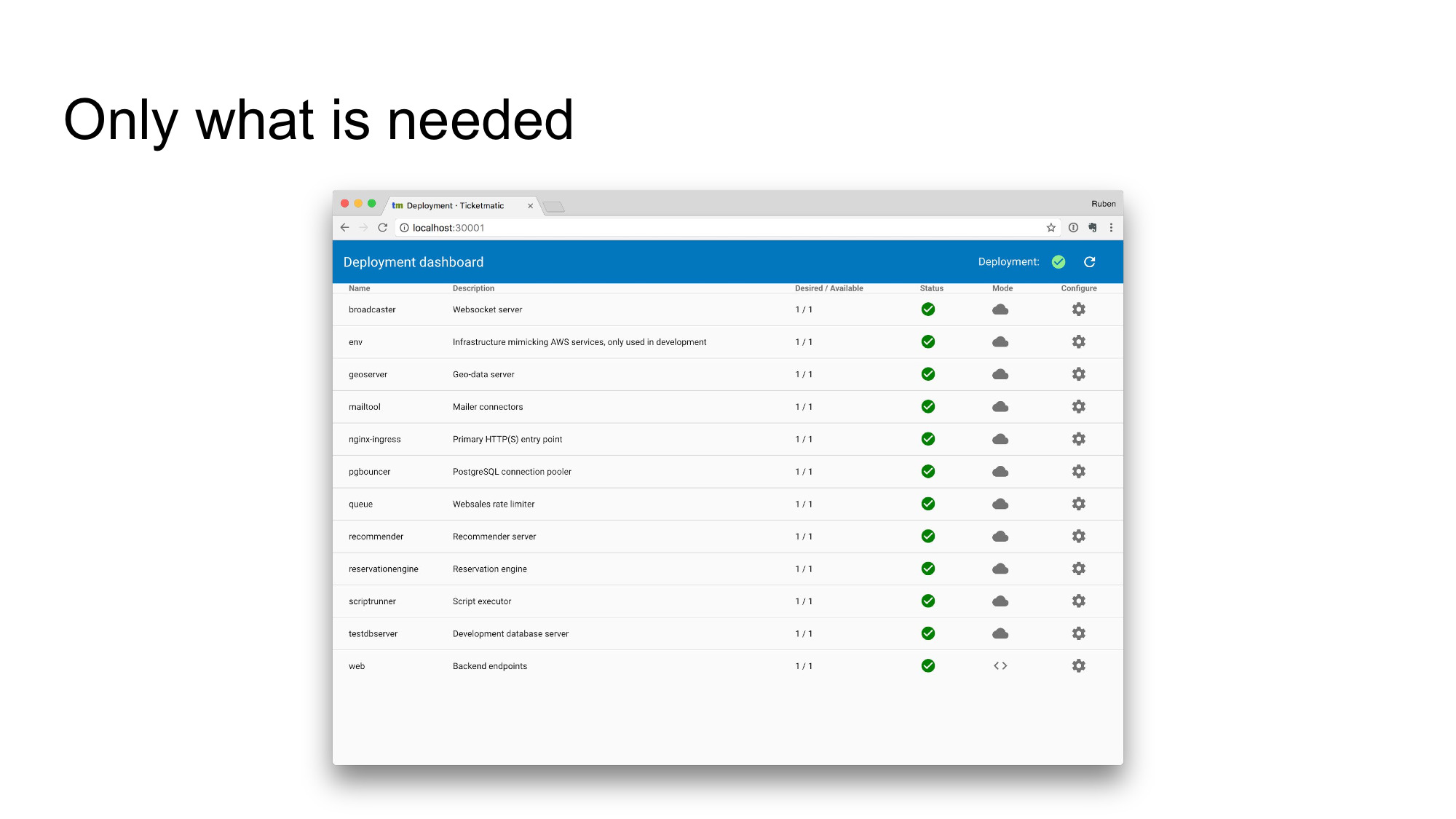
Devmatic exposes a web interface, which serves as the dashboard to our development environment.
Note that Kubernetes already has a graphical UI, the Kubernetes Dashboard. This one is equivalent feature-wise to kubectl, which makes it way too powerful for our purposes. New users get lost in the abundance of things to do.
The main screen is, intentionally, simple. We figured that for development environments, you’ll usually only run one instance of each service. That means there’s a 1:1 mapping between deployments and the underlying pods. Most developers don’t even care about pods, so we only show deployments (if your needs differ, you’re already an expert, you’ll know what to do).
This gives you a quick view on whether things are running OK.
There’s one main action on the top right: the reload button (for lack of a better icon). It triggers a redeployment of the platform, which will cause all services to be updated. This way it’s one click to sync your local development environment up to the latest and greatest version.
Also note the Mode column with all the cloud icons. These indicate that each of these services run the latest image built through our continuous integration system, the ones that will end up in production. We’ll get back to that.
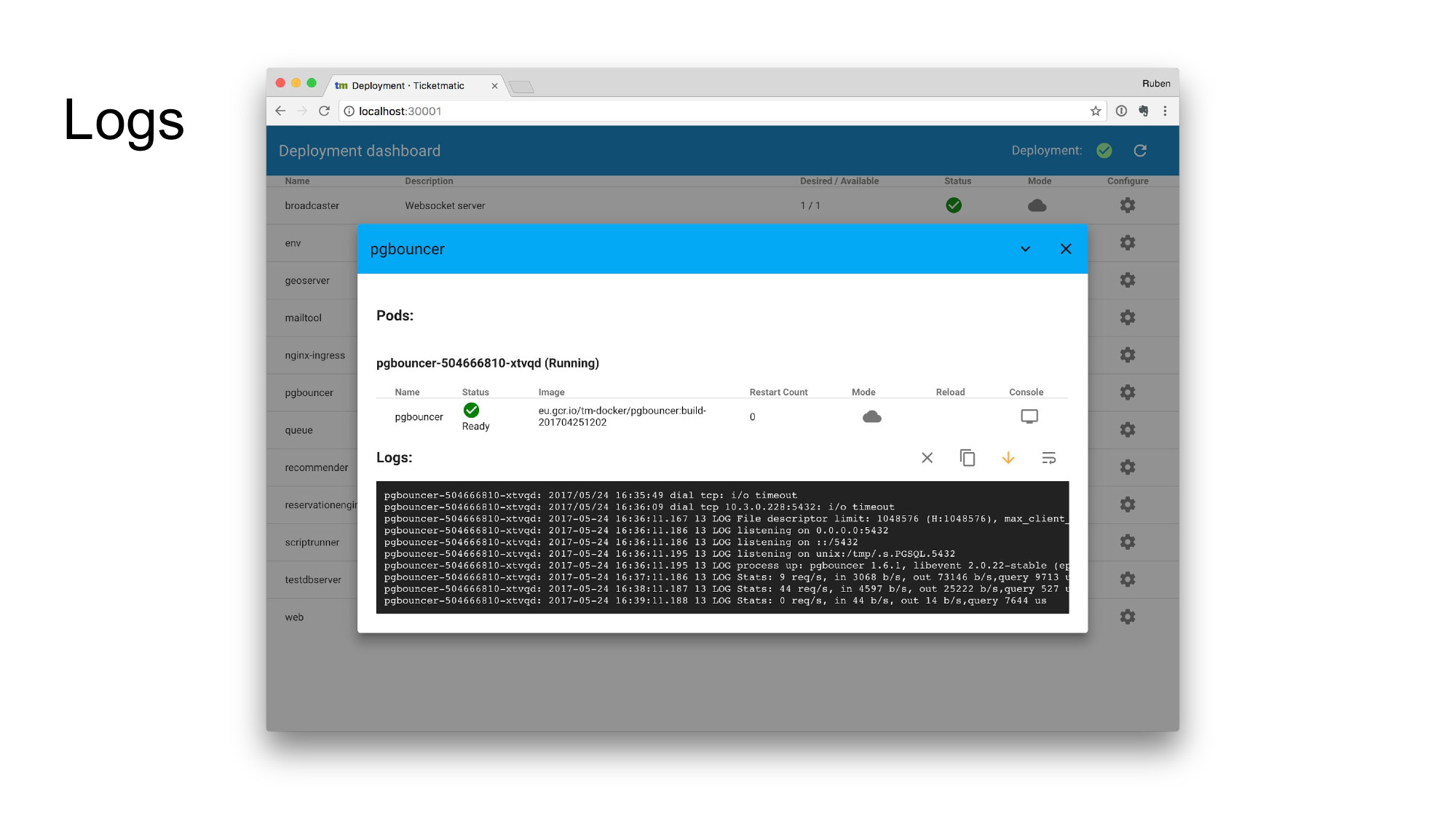
Clicking on a service will open up the details screen. This shows pod status, but also the latest log output of this service. This may seem trivial, but with ever-changing pod identifiers, it saves a ton of hassle. Rather than having to copy-paste the pod name into an invocation of kubectl every time, logs are directly available for viewing, in a live-tailing window.
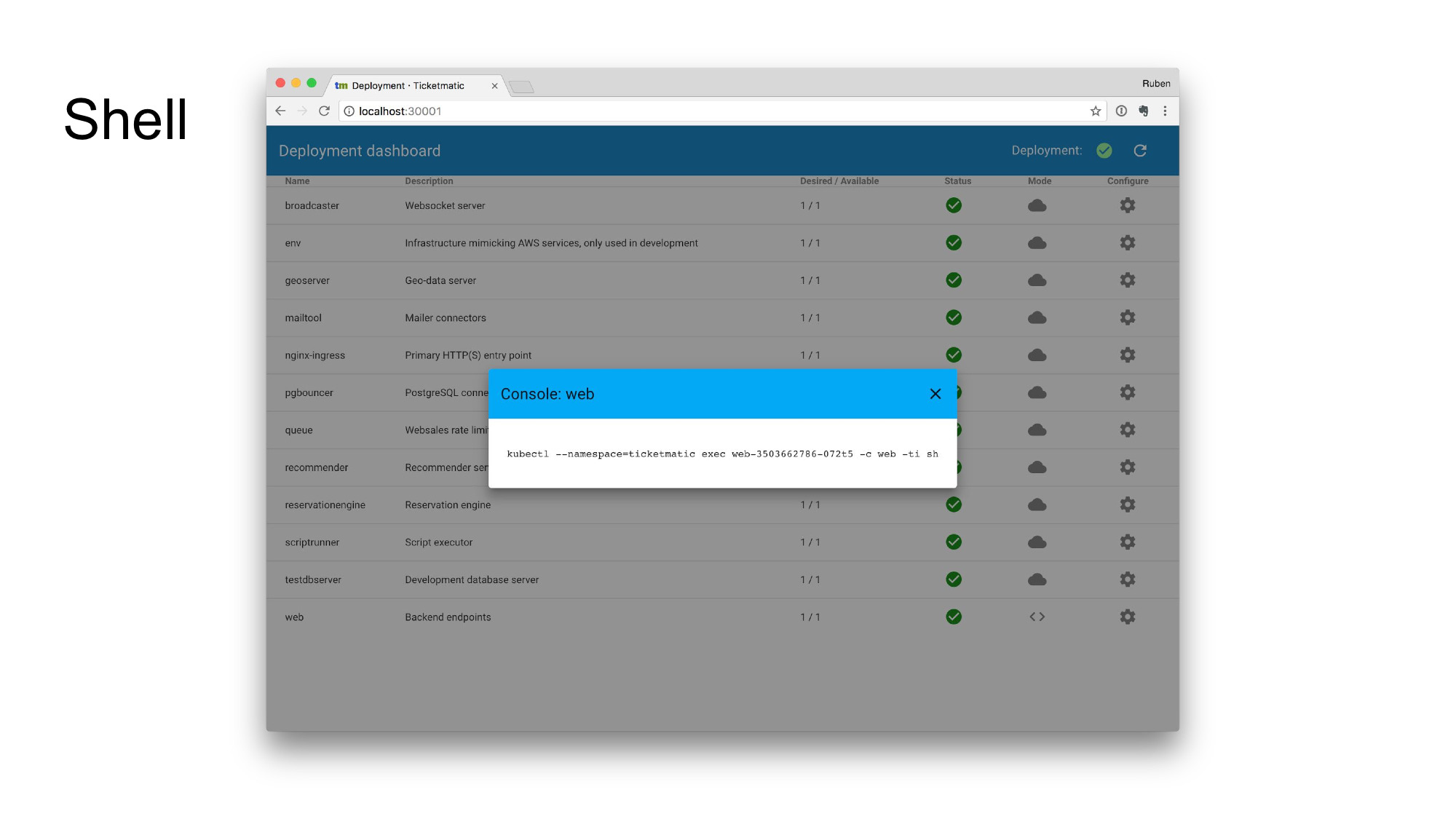
There’s also a button that gives you a copy-pastable command to drop into a shell within the container. We could’ve gone much further and embed a JavaScript terminal here, but those usually aren’t very nice and that would’ve been a lot of work. This is fine and works well for us. Good enough.
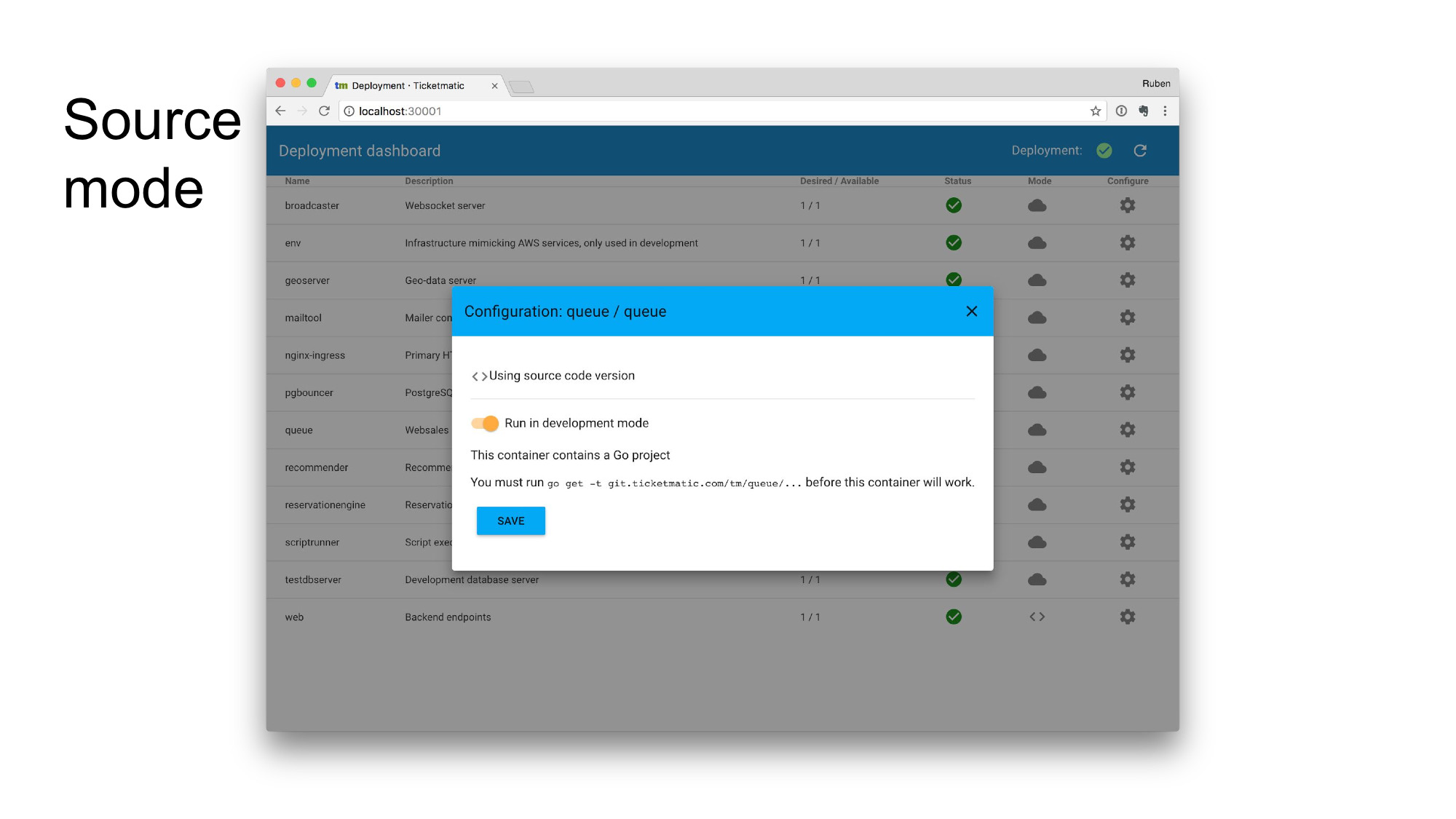
Source mode is one of the cooler features. Remember how each image was running with the pre-baked container image? Well, source mode allows you to change that. Toggle the switch and the container is reconfigured to use the source-code from your local machine, which is mounted into the container using a volume.
A reload button is then available to restart your service. This means you can simply edit source-code, hit the button and things will be restarted. Note that this doesn’t create new pods or anything: it restarts the service in the existing pod. This makes the process nearly instant. Live-reload for backend services!

The service that serves all of this up is called deploy-manager. It’s running in the Kubernetes cluster itself (in a different namespace) and it’s a combination of the dashboard + kube-appdeploy. The Kubernetes client-go library is used to interface with the Kubernetes API.
To borrow terminology from CoreOS: it’s a self-driving deployment: deploy-manager will periodically check for updates and, if needed, adjust it’s own configuration in Kubernetes. This leads to hassle-free automatic updates and ensures that all of our developers are on the latest version of our development environment.
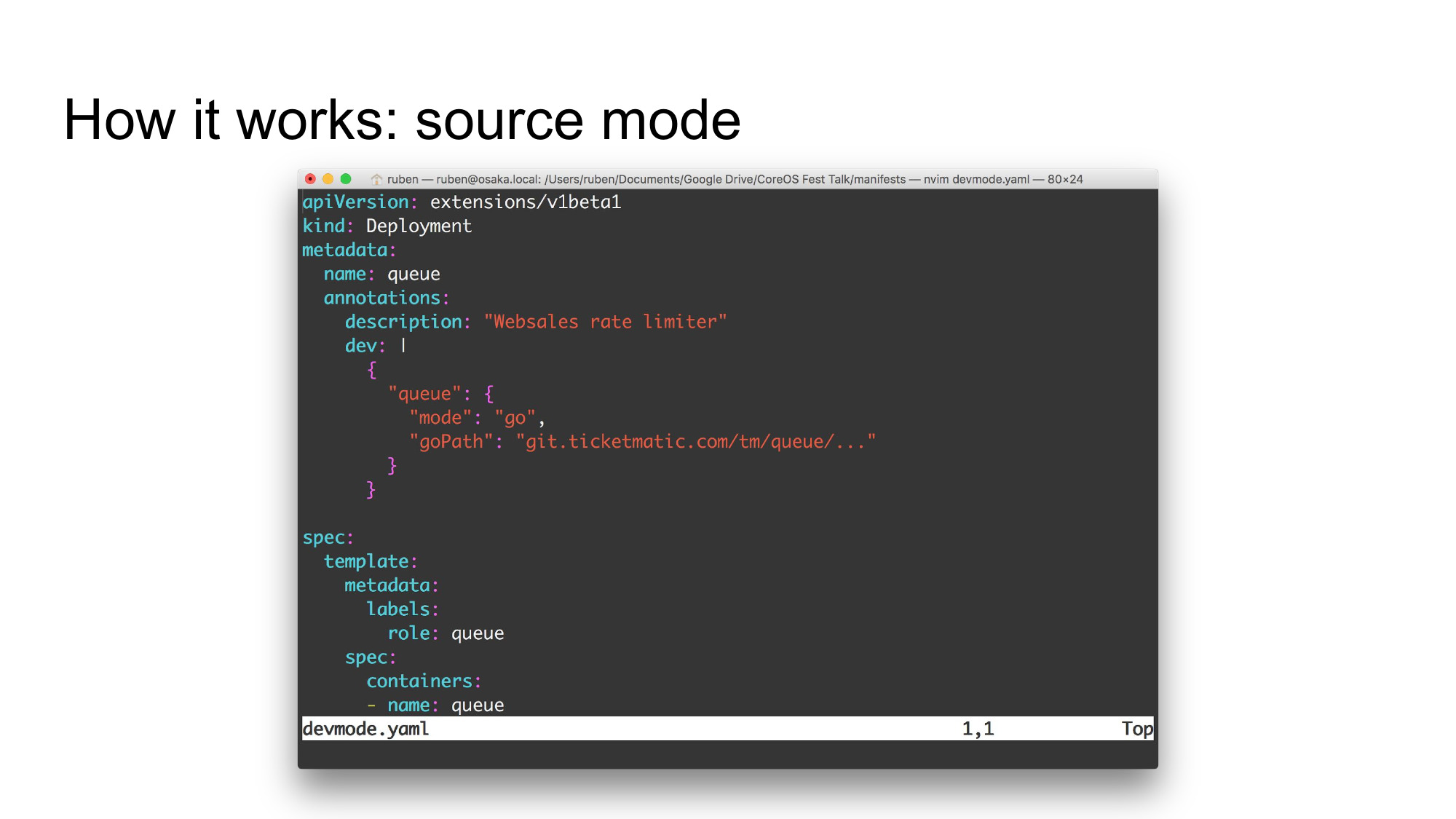
The dashboard knows which services implement source mode (and how they do so) by looking at the annotations of each deployment. A small bit of configuration is added to indicate which container is supported and how. In the example above, the queue container is a Go project. The import path is also indicated to help users set up their local environment when enabling source mode.
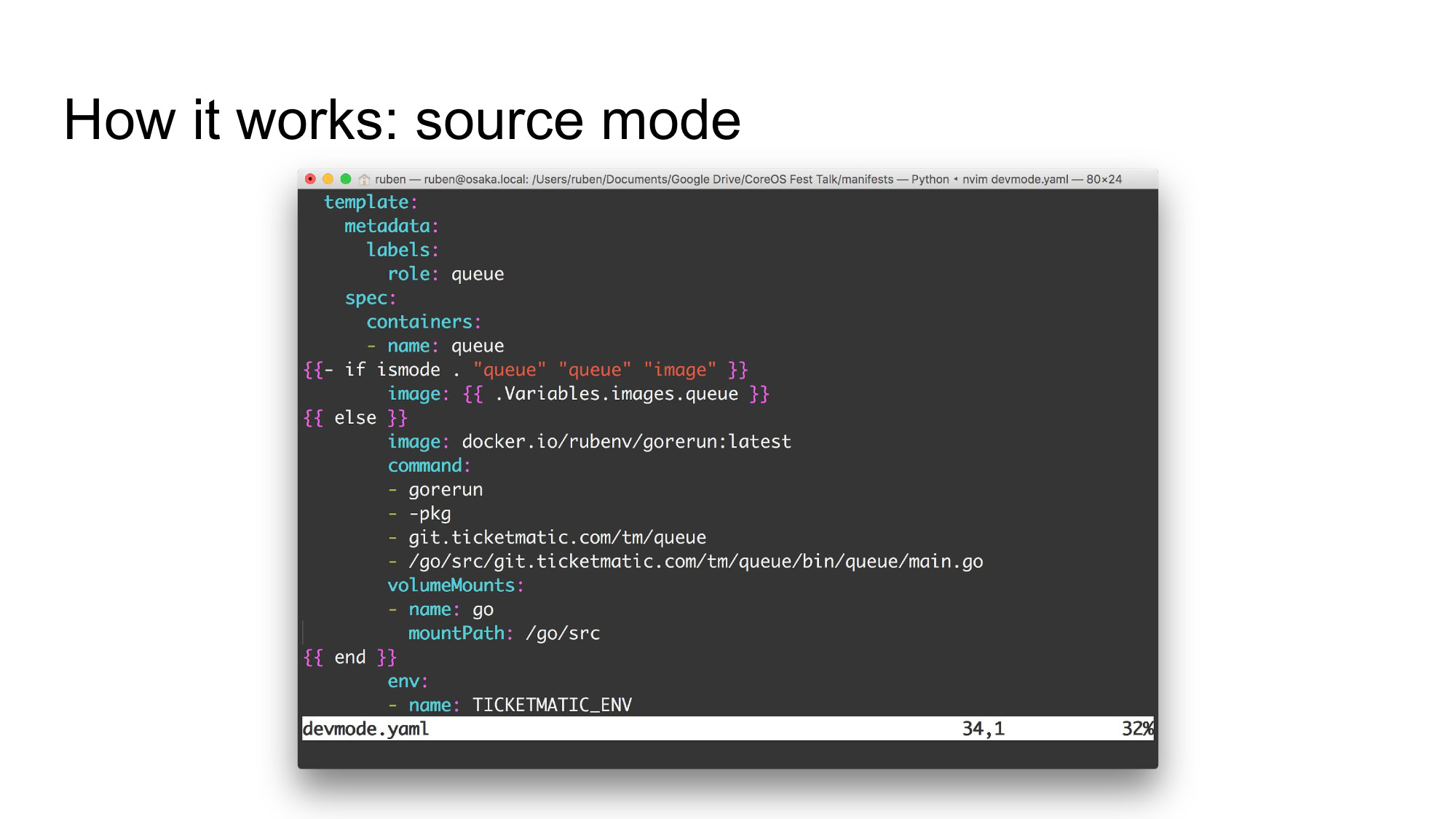
A second change is required in the deployment configuration: there’s a bit of control flow that switches between image mode and source mode. In image mode we use the image built by our continuous integration system, with the image reference being filled in using a variable.
Switch to source mode and we’ll switch to a different base image, dependent on the project language. In the case of a Go project, we use gorerun, which is the containerized equivalent of go run, which can be poked to restart the process (it does some smart caching to make this nearly instant).
This isn’t ideal: there’s a small mismatch between a production image and the development version, but it’s minor. Be sure to do integration testing on the final built image as well and you’re good.

The result?
A trouble-free uptake! We went to great lengths to ensure that mapped ports remained the same, so developers could simply throw out the old Vagrant image, install the new environment and things just worked. They also got a couple of nice extra features to make their lives easier.
Letting the development environment update itself saves a pile of work, it also ensures that no weird effects happen due to working in an outdated setup. Definitely recommended.

But the sad truth is that we shouldn’t have had to build this. We’re a ticketing company, not a developer tools vendor, so having to build a lot of tooling just to get our job done feels wrong.

Time for some conclusions!

Going cloud-native is a bigger change than just some new infrastructure: it affects the whole development cycle and I recommend you pay close attention to this fact. Invest in great processes and experiences: it’ll make adoption easier and pays of royally in terms of increased productivity.
Also realize that it’s quite normal to be confused. There are so many options and posibilities related to Kubernetes, so getting started can be quite daunting.
But don’t let this discourage you: the curve might be steep at times, but the rewards are big.
Kubernetes is one of the most solid and stable tools we’ve ever used. It’s amazing how much can go wrong in your software, with Kubernetes still managing to keep it running and available.

Let me re-iterate that building from the ground up is absolutely the right way to do things. It has given us solid foundations and as we all know, you can’t build anything on top of a house of cards.
But as a project / community, we have to realize that all these undefineds quickly turn into something highly confusing. We might risk losing users because they’re lost.
Or worse, everyone may continue to make this same effort over and over again.
So we should ask ourselves, can we streamline this a bit? Are there things to standardise? I hate the word standardise, but it’s probably the right one in this context.
This morning the people from Deis/Microsoft announced Draft, a developer workflow tool that solves many (not all) of these problems. That’s a great step in the right direction. My gut feeling is that a combination of Helm and minikube may provide a good platform to ease this problem.
So let’s exchange experiences, talk about how you may have tackled this problem. Perhaps we can set something in motion here to make working with Kubernetes even more awesome.

Thanks for reading up to this point. I must also mention that we’re always looking for great people, either in Belgium, The Netherlands or in San Francisco. We’re both looking for people that love a new technical challenge as well as those that want to help us conquer new markets. Let’s talk!