dupefinder - Removing duplicate files on different machines
Imagine you have an old and a new computer. You want to get rid of that old computer, but it still contains loads of files. Some of them are already on the new one, some aren’t. You want to get the ones that aren’t: those are the ones you want to copy before tossing the old machine out.
That was the problem I was faced with. Not willing to do this tedious task of comparing and merging files manually, I decided to wrote a small tool for it. Since it might be useful to others, I’ve made it open-source.
Introducing dupefinder
Here’s how it works:
- Use dupefinder to generate a catalog of all files on your new machine.
- Transfer this catalog to the old machine
- Use dupefinder to detect and delete any known duplicate
- Anything that remains on the old machine is unique and needs to be transfered to the new machine
You can get in two ways: there are pre-built binaries on Github or you may use go get:
go get github.com/rubenv/dupefinder/...
Usage should be pretty self-explanatory:
Usage: dupefinder -generate filename folder...
Generates a catalog file at filename based on one or more folders
Usage: dupefinder -detect [-dryrun / -rm] filename folder...
Detects duplicates using a catalog file in on one or more folders
-detect=false: Detect duplicate files using a catalog
-dryrun=false: Print what would be deleted
-generate=false: Generate a catalog file
-rm=false: Delete detected duplicates (at your own risk!)
Technical details
Dupefinder was written using Go, which is my default choice of language nowadays for these kind of tools.
There’s no doubt that you could use any language to solve this problem, but Go really shines here. The combination of lightweight-threads (goroutines) and message-passing (channels) make it possible to have clean and simple code that is extremely fast.
Internally, dupefinder looks like this:
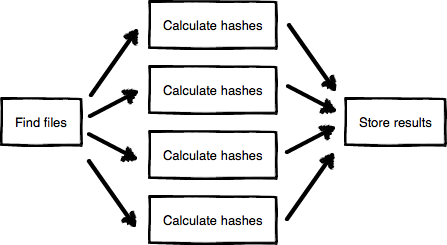
Each of these boxes is a goroutine. There is one hashing routine per CPU core. The arrows indicate channels.
The beauty of this design is that it’s simple and efficient: the file crawler ensures that there is always work to do for the hashers, the hashers just do one small task (read a file and hash it) and there’s one small task that takes care of processing the results.
The end-result?
A multi-threaded design, with no locking misery (the channels take care of that), in what is basically one small source file.
Any language can be used to get this design, but Go makes it so simple to quickly write this in a correct and (dare I say it?) beautiful way.
And let’s not forget the simple fact that this trivially compiles to a native binary on pretty much any operationg system that exists. Highly performant cross-platform code with no headaches, in no time.
The distinct lack of bells and whistles makes Go a bit of an odd duck among modern programming languages. But that’s a good thing. It takes some time to wrap your head around the language, but it’s a truly refreshing experience once you do. If you haven’t done so, I highly recommend playing around with Go.
Random questions
- How does it compare files?: It uses SHA256 hashes for each file.
- I deleted all my data and will sue!: Use this tool 100% at your own risk!
- Help!: Questions and problems on Github please.